If you follow GEO or AI search, you’ve probably seen llms.txt come up as a recommended tactic. Add it to your site. Help AI systems understand your content. Stay ahead of the curve.
What nobody’s actually done is measure how many sites have done it.
So I did. Using HTTP Archive’s BigQuery dataset, which covers crawl data for millions of websites, I ran the queries and pulled the numbers. Here’s what the web actually looks like.
What llms.txt is (the quick version)
/llms.txt is a proposed standard, first published in late 2024. The idea: put a Markdown file at your domain root that gives AI systems a clean, structured summary of your site. Key pages, content hierarchy, what you want agents and LLMs to actually find. Think robots.txt, but for comprehension rather than access control.
There’s also /llms-full.txt, a longer version with more detail. Neither is an official standard. Both are community proposals that have gained real traction in the AI search space.
How I measured this
HTTP Archive runs a monthly crawl of millions of websites and stores the results in public BigQuery datasets. Their custom metrics include a llms_txt_validation field that fetches /llms.txt for each crawled site and validates whether it returns a real, parseable file (not a soft-404 HTML page dressed as a 200 OK).
A few things to keep in mind before we get into numbers:
- The metric only started in July 2025. HTTP Archive didn’t track llms.txt before that crawl, so our dataset covers exactly 12 months.
- “Valid” means parseable, not high-quality. An auto-generated stub counts the same as a handcrafted file. Presence doesn’t tell us anything about usefulness.
- The crawl is CrUX-origin based. HTTP Archive tracks sites with real Chrome user traffic, not a random sample of every URL that exists. That’s actually appropriate here.
/llms-full.txtisn’t tracked separately in the current dataset. Everything below is about/llms.txtonly.
The headline number
5.61% of the top 10,000 websites have a valid llms.txt as of June 2026.
That’s 421 sites out of 7,504 crawled in the top-10k. Low in percentage terms, but across the full top-1M that translates to roughly 39,000 sites.
Adoption doesn’t drop off with rank
This is the finding that surprised me most. You’d expect llms.txt to be concentrated in high-traffic sites with technical SEO teams watching emerging standards closely. The data doesn’t support that.
![]()
| Rank bucket | Adoption |
|---|---|
| Top 1,000 | 6.28% |
| Top 10,000 | 5.61% |
| Top 100,000 | 5.17% |
| Top 1,000,000 | 5.07% |
A 1.2 percentage point spread from the top 1k all the way to the top 1M. That’s surprisingly flat. It suggests llms.txt is spreading broadly rather than concentrating at the elite end of the web. Part of the reason why becomes clear when you look at the platform data.
12 months of growth
July 2025 is our baseline: 1.04% of the top-10k had a valid llms.txt file. By June 2026, that’s 5.61%. Roughly 5.4x growth in 12 months.
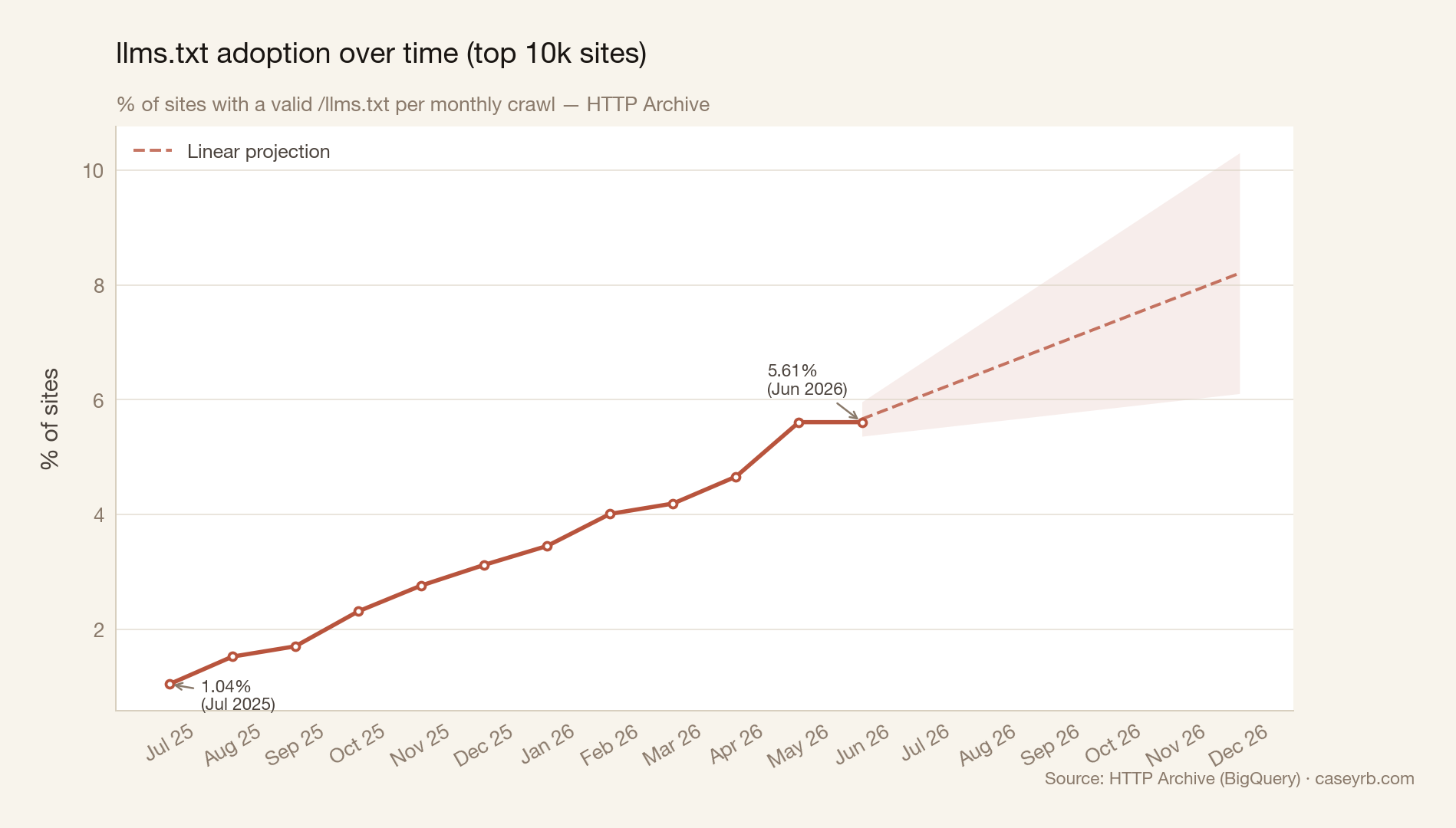
Growth was consistent through late 2025, then picked up pace through early 2026. May and June 2026 both sit at 5.61%, the first flat reading in the dataset. That said, the most recent crawl can still be settling, so I wouldn’t read too much into a single flat month. If the trend holds linearly, adoption in the top-10k could reach around 8% by the end of 2026.
The platform factor
The CMS and platform breakdown is where it gets interesting.
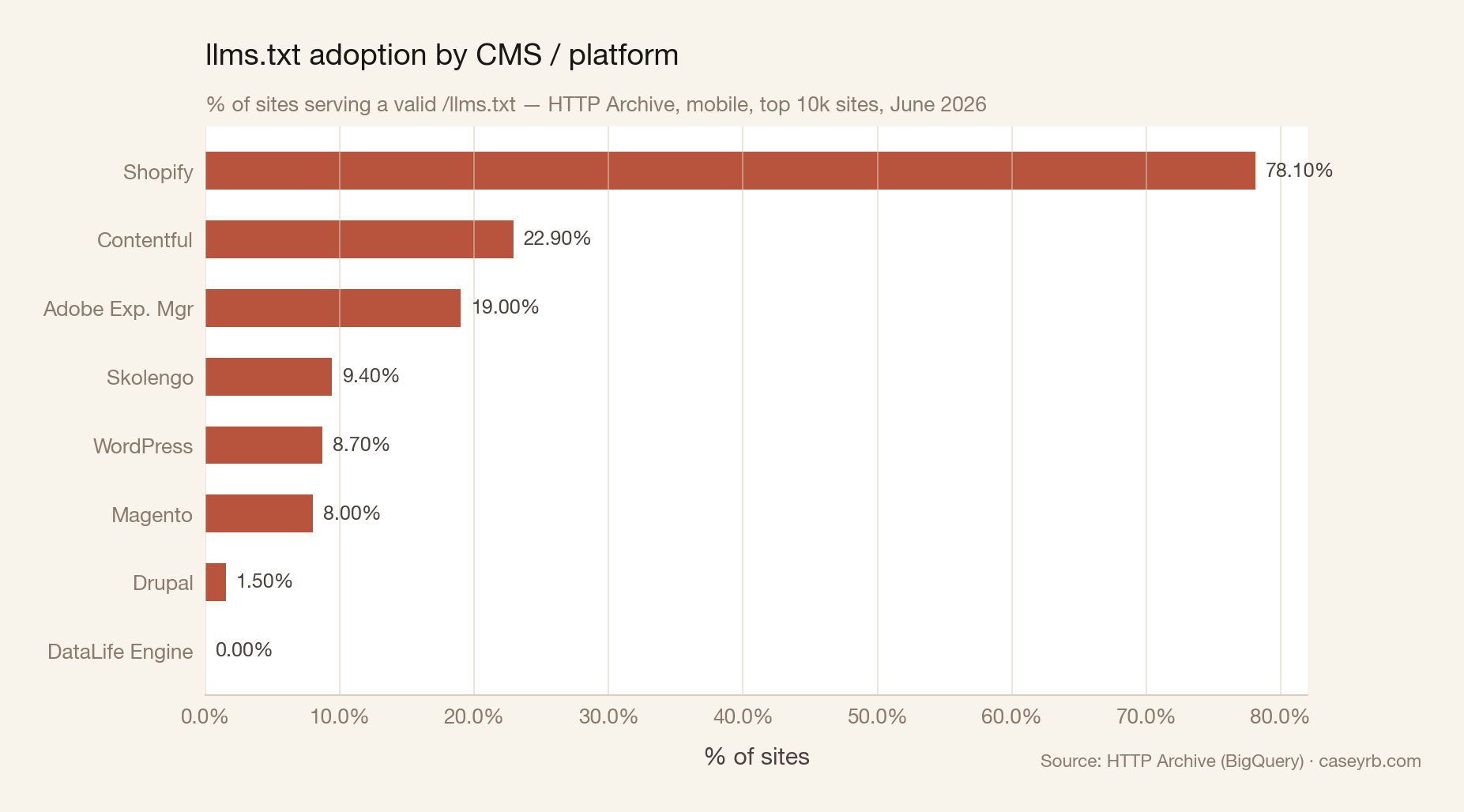
Shopify at 78.1% stands out immediately. That number isn’t organic developer adoption.
In late April and early May 2026, Shopify silently pushed llms.txt (and /llms-full.txt, /agents.md, and several other agent-facing endpoints) to every store on the platform by default. No opt-in, no merchant notification, no announcement. The first official acknowledgment was a developer changelog entry on May 28, 2026, three weeks after people started noticing.
Shopify’s 78.1% is a platform decision, not a signal of developer enthusiasm. The number will trend toward 95%+ as the rollout finishes covering headless Shopify stores.
WordPress at 8.7% is the more meaningful figure for most people reading this. It reflects actual human decisions: someone installed a plugin, or someone sat down and wrote the file. Contentful at 22.9% and Adobe Experience Manager at 19% suggest enterprise CMS users are taking this more seriously than the long tail. Drupal at 1.5% is low and probably reflects a lack of community tooling rather than deliberate choice.
Who actually has one
Looking at sites with a valid llms.txt, here are some recognisable names, grouped by where they rank:
| Site | Rank tier |
|---|---|
| GitHub | Top 1,000 |
| Adobe | Top 1,000 |
| Samsung | Top 1,000 |
| Target | Top 1,000 |
| PayPal | Top 1,000 |
| LG | Top 1,000 |
| SHEIN | Top 1,000 |
| Weather.com | Top 1,000 |
| Times of India | Top 1,000 |
| Argos | Top 1,000 |
| Dailymotion | Top 1,000 |
| Apple Music | 1,000–10,000 |
| McDonald’s | 1,000–10,000 |
| PlayStation | 1,000–10,000 |
| Vercel | 1,000–10,000 |
| Cleveland Clinic | 1,000–10,000 |
One honest note: the adopter list also includes a cluster of spam and gambling domains that appear to be auto-generating llms.txt to look more legitimate to AI crawlers. They count as “valid” in the HTTP Archive data. It’s a small inflator in the headline number, but worth naming.
The reality check: the AI front doors don’t have one
The most interesting finding isn’t who has it. It’s who doesn’t.
| Site | Has llms.txt |
|---|---|
| chatgpt.com | No |
| claude.ai | No |
| gemini.google.com | No |
| openai.com | No |
| anthropic.com | No |
| huggingface.co | No |
| character.ai | No |
The products that would theoretically read these files haven’t added one to their own domains. Not one of the major consumer AI platforms has a valid /llms.txt.
But there’s a more revealing split inside the AI labs themselves. The consumer apps and marketing sites have nothing, but the developer documentation tells a different story. I checked the docs site for each major lab:
| AI lab (docs site) | Has llms.txt |
|---|---|
| Anthropic (docs.anthropic.com) | Yes |
| xAI / Grok (docs.x.ai) | Yes |
| Perplexity (docs.perplexity.ai) | Yes |
| Mistral (docs.mistral.ai) | Yes |
| Cohere (docs.cohere.com) | Yes |
| OpenAI (platform.openai.com) | No |
| Google / Gemini (ai.google.dev) | No |
The pattern is neat: the two biggest incumbents, OpenAI and Google, don’t serve one, while the challengers do. And where the standard shows up isn’t the marketing site or the consumer app, it’s the docs. The people thinking hardest about machine-readable content are the documentation teams. (xAI’s is the largest I found anywhere at ~1.2MB.)
I’m not pointing this out to call anyone out. If anything, that split is itself a clue. The labs haven’t ignored llms.txt, they’ve added it exactly where it seems to earn its keep: on the documentation that AI tools are constantly asked to read and reason about. The consumer front doors and marketing pages, where the payoff is far less obvious, mostly go without.
Should you add one?
Probably, because it’s low effort.
A minimal llms.txt is 15 minutes of work. You’re not restructuring your site or investing in tooling. The downside of not having one is close to zero right now. The potential upside, as AI agents and retrieval systems mature, is a cleaner signal for how your content gets understood and surfaced.
The honest uncertainty is whether llms.txt actually influences how AI systems cite your content. We don’t know yet. None of the major AI search providers have publicly confirmed they read these files. The spec is still a proposal, not a standard.
What I’d say is this: structured, machine-readable signals have a track record on the web. Schema markup took years to matter and is now expected for rich results. robots.txt was proposed in 1994 and every major crawler respects it today. llms.txt might follow a similar arc. Adding it now is cheap. Waiting costs you nothing either, unless adoption accelerates faster than expected.
And if I had to guess where it lands, the docs pattern is the tell. llms.txt looks most useful where an AI is actively consuming technical, instructional content to do a job, like writing code against an API. That’s exactly the context the labs adopted it in. For a marketing site, the value is murkier, and I wouldn’t claim it’s moving the needle yet. Treat that as a hunch, not a finding.
The bigger investment is making your site genuinely readable for AI systems, not just discoverable. That means structured data, semantic HTML, clear content hierarchy. If you want a framework for that, my guide to auditing your site for AI agent readiness covers it in detail, and the 7 pillars of GEO is how I think about the full picture. If you want to see whether any of this is actually moving your traffic numbers, setting up an AI referral traffic dashboard takes about five minutes.
The file is easy. The strategy takes longer. Start with the file.
